---
title: "Accordo e Rasch Part III"
format:
html:
page-layout: full
toc: true
toc-location: left
code-tools:
source: true
toggle: false
caption: none
editor: source
execute:
eval: true
echo: false
theme: minty
---
```{r}
#| warning: false
#| message: false
library(ggplot2)
library(psych)
library(TAM)
library(knitr)
library(patchwork)
library(lavaan)
```
# Descrittive
::: {.panel-tabset}
## Distrattori vs corrette (tra Set)
```{r}
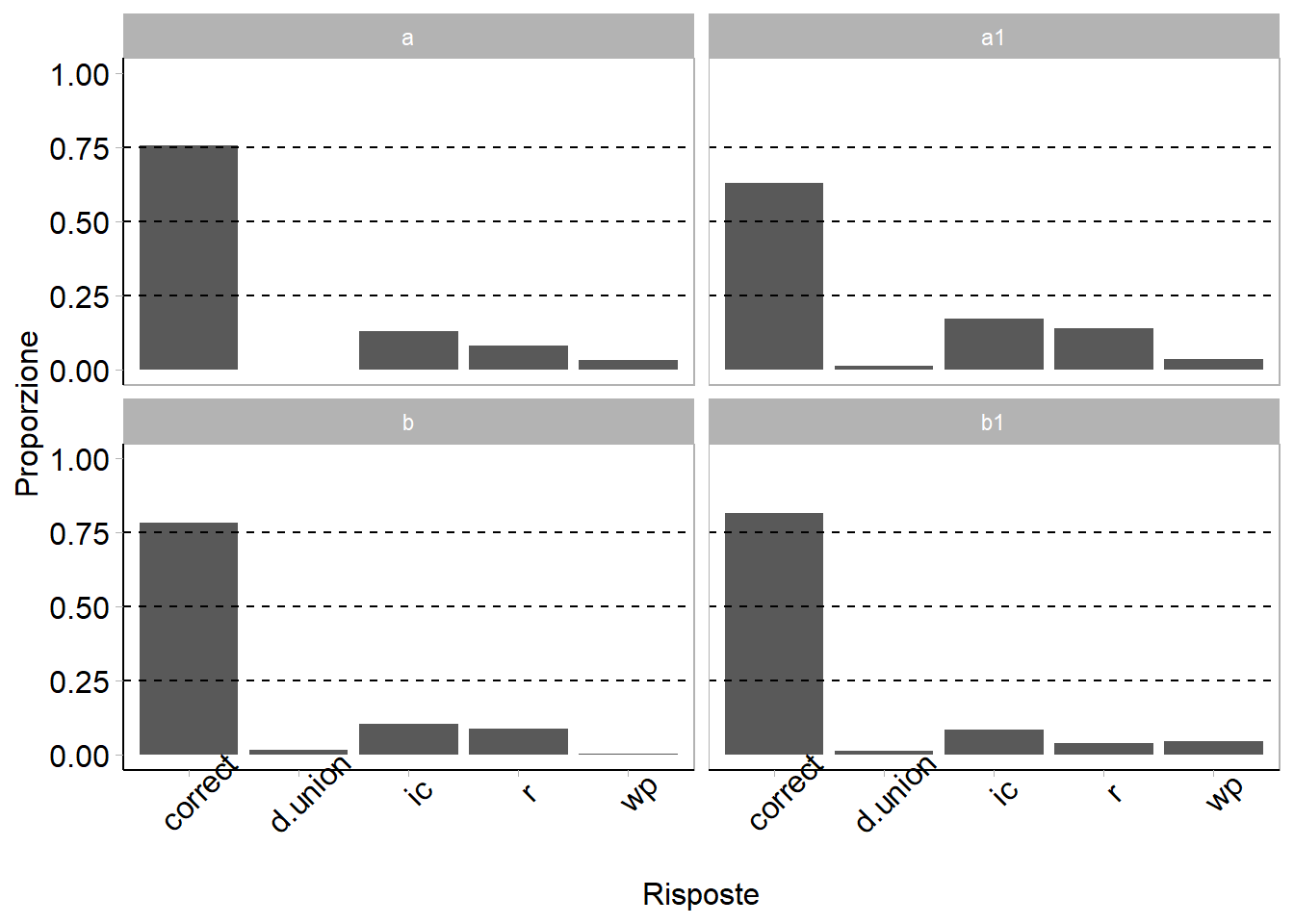
#| fig-cap: Proporzione di opzioni di risposta scelte per ogni set, attraverso gli anni
#| fig-subcap: Proporzioni calcolate sul totale delle risposte
#| fig-cap-location: top
data = read.csv("data/data_recode.csv",
header =T,
sep = ",")
# facciamo pulizia
data = data[data$data.accetto.non.accetto %in% 1, ]
data = data[!data$data.DistributionChannel %in% "preview", ]
data = data[!grepl("13/12", data$data.StartDate), ]
# prendo solo i dati completi
d = data[data$data.Finished %in% 1, ]
d.move = d
d.move$temp.a1_1 = d$a_1
d.move$temp.a_1 = d$a1_1
d.move$a_1 = NULL
d.move$a1_1 = NULL
d.move$a_1 = d.move$temp.a_1
d.move$a1_1 =d.move$temp.a1_1
d.move$temp.a1_1 = NULL
d.move$temp.a_1 = NULL
# rinomino i distrattori
d.r = d[, -c(1:4)]
for (i in 1:nrow(d.r)) {
for (j in 1:ncol(d.r)) {
if (is.na(d.r[i,j]) == T) {
d.r[i,j] = d.r[i,j]
} else if (d.r[i,j] == "correct") {
d.r[i,j] = d.r[i,j]
} else if (d.r[i, j] == "wp.copy.ic.flip") {
d.r[i, j] = "ic"
} else if (grepl("ic.", d.r[i,j]) ==T) {
d.r[i,j] = "ic"
} else if ( grepl("r.", d.r[i,j])) {
d.r[i,j] = "r"
} else if (grepl("wp.", d.r[i,j])) {
d.r[i,j] = "wp"
}
}
}
d.r.temp = d.r[,-1]
d.r.l = stack(d.r.temp)
d.r.l$ind = as.character(d.r.l$ind)
d.r.l$set = gsub("_.*", "", d.r.l$ind)
d.set = data.frame(table(d.r.l$values, d.r.l$set))
d.set$tot = 245
d.set$prop = d.set$Freq/d.set$tot
ggplot(d.set,
aes(x = Var1, y = prop)) + geom_bar(stat = "identity") + facet_wrap(~Var2) + scale_y_continuous(breaks=c(0,.25,.50, .75, 1.00),
limits = c(0, 1.00)) +
labs(
y = "Proporzione",
x = "Risposte")+
theme_light()+
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black"))+
theme(axis.text.y = element_text(size=12, color="black"),
axis.title.y = element_text(size=12),
axis.text.x = element_text(size=12, color="black",
angle = 45),
axis.title.x = element_text(size=12),
title = element_text(size=12))+
geom_hline(yintercept=.25, linetype="dashed")+
geom_hline(yintercept=.50, linetype="dashed")+
geom_hline(yintercept=.75, linetype="dashed")
```
## Distrattori vs. corrette (quaterne)
```{r}
mycol = RColorBrewer::brewer.pal(12, "Paired")[c(1:2, 5:6)]
d.item = data.frame(table(d.r.l$values, d.r.l$ind))
d.item$tot = 35
colnames(d.item) = c("values", "ind", "freq", "tot")
d.item$prop = d.item$freq/d.item$tot
d.item$set = gsub("_.*", "", d.item$ind)
d.item$set = gsub("[0-9]", "", d.item$set)
d.item$couple = as.integer(gsub("\\D", "", d.item$ind))
d.item$couple = ifelse(d.item$couple > 10,
"1", "0")
d.item$type = 0
d.item[-c(grep("logic", d.item$ind),
grep("visuo", d.item$ind)), "type"] = paste0("visuo",
gsub(".*_", "", d.item[-c(grep("logic", d.item$ind),
grep("visuo", d.item$ind)), "ind"]))
d.item[c(grep("logic", d.item$ind),
grep("visuo", d.item$ind)), "type"] = gsub(".*_", "", d.item[c(grep("logic", d.item$ind),
grep("visuo", d.item$ind)), "ind"])
d.item$new.var = paste(d.item$set,
d.item$couple, sep = ".")
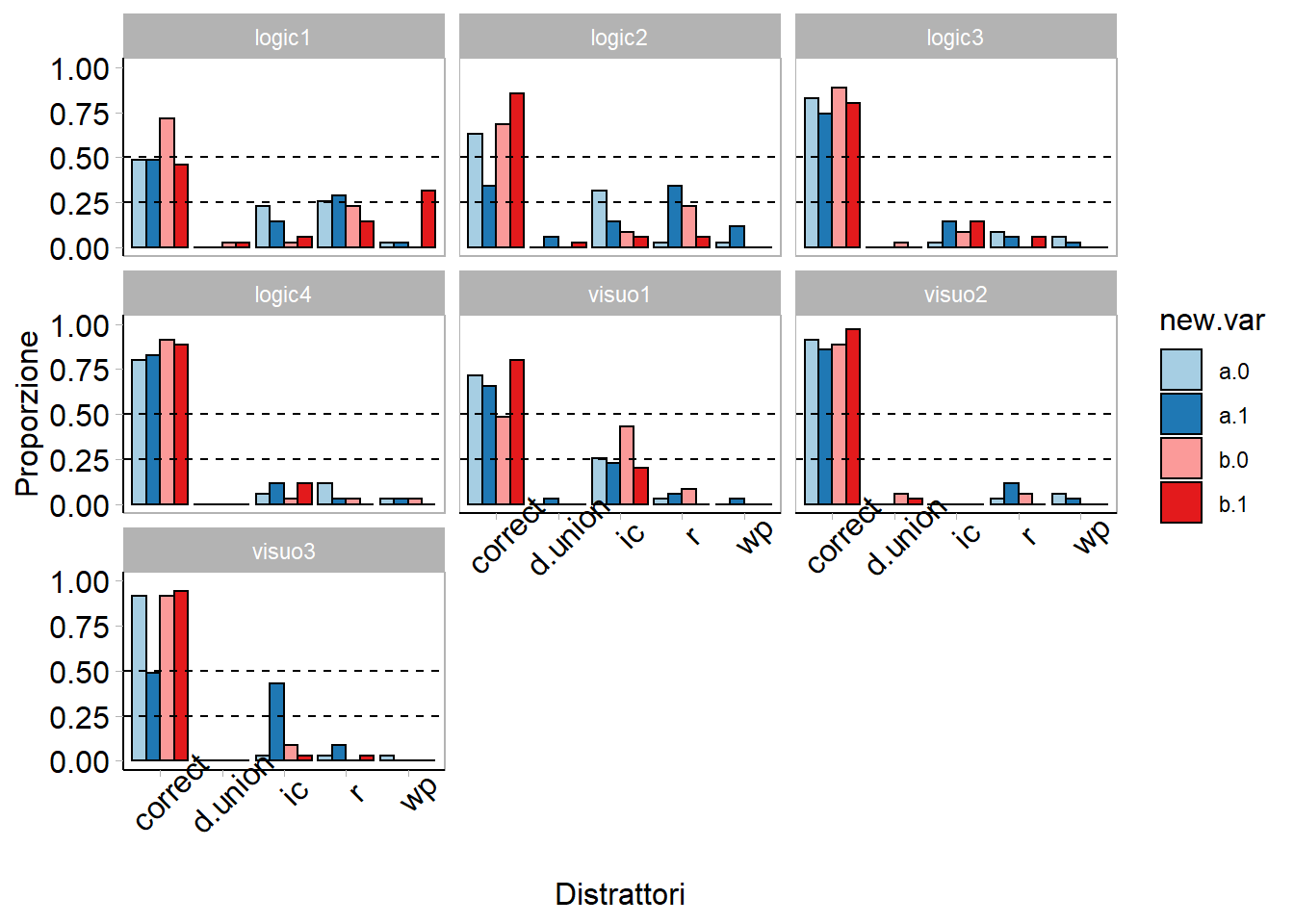
ggplot(d.item,
aes(x = values, fill = new.var, y = prop)) + geom_bar(colour = "black", stat = "identity", position = position_dodge()) + facet_wrap(~type) + scale_y_continuous(breaks=c(0,.25,.50, .75, 1.00),
limits = c(0,1.0)) +
labs(
y = "Proporzione",
x = "Distrattori")+
theme_light()+
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black"))+
theme(axis.text.y = element_text(size=12, color="black"),
axis.title.y = element_text(size=12),
axis.text.x = element_text(size=12, color="black",
angle = 45),
axis.title.x = element_text(size=12),
title = element_text(size=12))+
geom_hline(yintercept=.25, linetype="dashed")+
geom_hline(yintercept=.50, linetype="dashed")+
geom_hline(yintercept=.50, linetype="dashed") + scale_fill_manual(values = mycol)
```
## Solo distrattori
```{r}
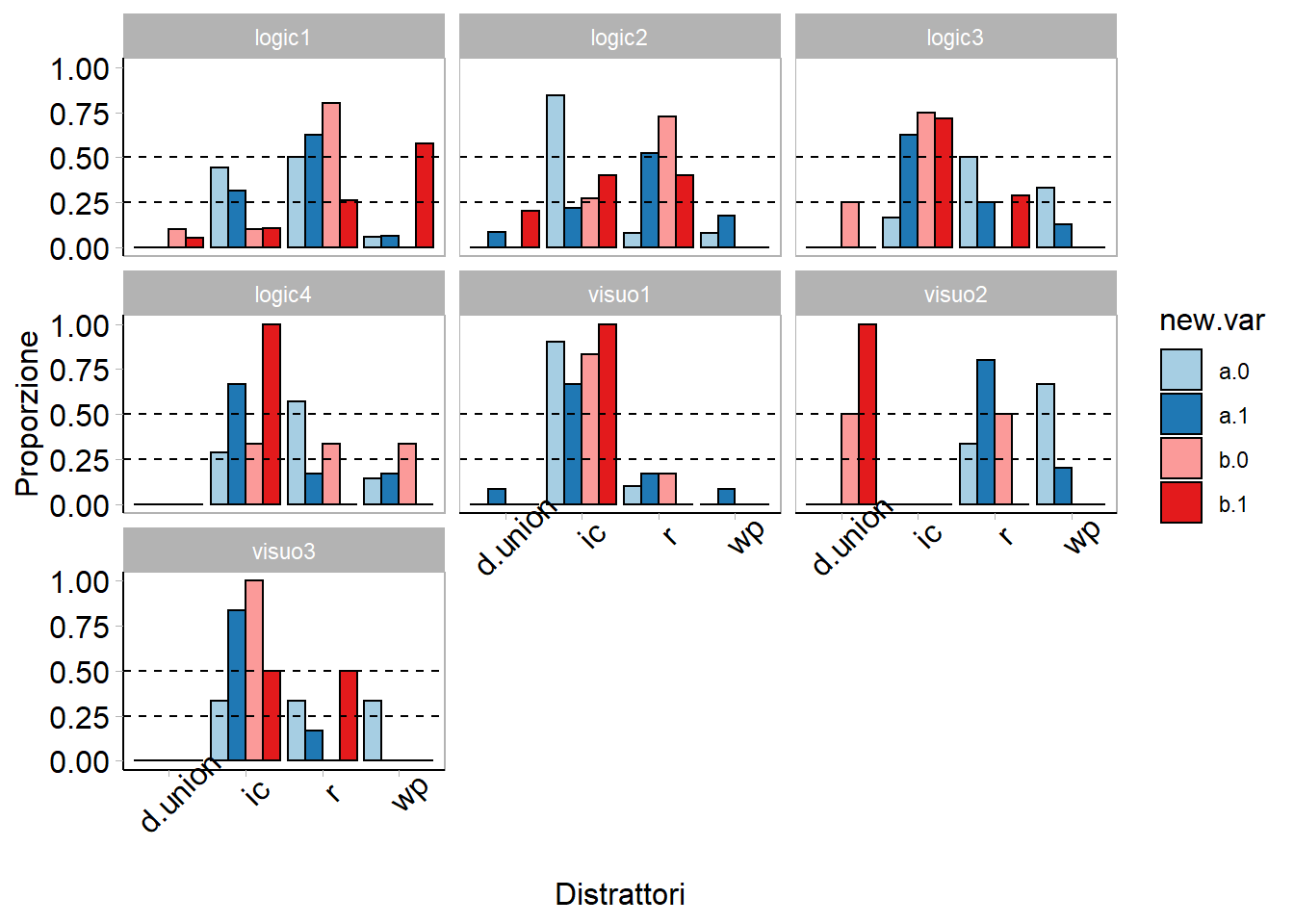
#| fig-cap: Proporzioni di distrattori scelti per ogni item
#| fig-subcap: Calcolate facendo riferimento al numero di risposte errate per ogni item
#| fig-cap-location: top
# togliendo tutte le risposte corrette, proporzione di distrattori scelti
# penso che lo farò per le quaterne di item
d.err = d.r.l[!d.r.l$values %in% "correct", ]
a = table(d.err$ind, d.err$values)
b = data.frame(rowSums(a))
b$item = rownames(b)
colnames(b)[1] = "tot"
d.err1 = data.frame(table(d.err$ind, d.err$values))
colnames(d.err1)[1] = "item"
d.err1 = merge(d.err1, b,
by = "item")
d.err1$prop = d.err1$Freq/d.err1$tot
d.err = d.err1
d.err$set = gsub("_.*", "", d.err$item)
d.err$set = gsub("[0-9]", "", d.err$set)
d.err$couple = as.integer(gsub("\\D", "", d.err$item))
d.err$couple = ifelse(d.err$couple > 10,
"1", "0")
d.err$type = 0
d.err[-c(grep("logic", d.err$item),
grep("visuo", d.err$item)), "type"] = paste0("visuo",
gsub(".*_", "", d.err[-c(grep("logic", d.err$item),
grep("visuo", d.err$item)), "item"]))
d.err[c(grep("logic", d.err$item),
grep("visuo", d.err$item)), "type"] = gsub(".*_", "", d.err[c(grep("logic", d.err$item),
grep("visuo", d.err$item)), "item"])
d.err$new.var = paste(d.err$set,
d.err$couple, sep = ".")
ggplot(d.err,
aes(x = Var2, fill = new.var, y = prop)) + geom_bar(colour = "black", stat = "identity", position = position_dodge()) + facet_wrap(~type) + scale_y_continuous(breaks=c(0,.25,.50, .75, 1.00),
limits = c(0,1.0)) +
labs(
y = "Proporzione",
x = "Distrattori")+
theme_light()+
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black"))+
theme(axis.text.y = element_text(size=12, color="black"),
axis.title.y = element_text(size=12),
axis.text.x = element_text(size=12, color="black",
angle = 45),
axis.title.x = element_text(size=12),
title = element_text(size=12))+
geom_hline(yintercept=.25, linetype="dashed")+
geom_hline(yintercept=.50, linetype="dashed")+
geom_hline(yintercept=.50, linetype="dashed") + scale_fill_manual(values = mycol)
```
:::
# Accordo
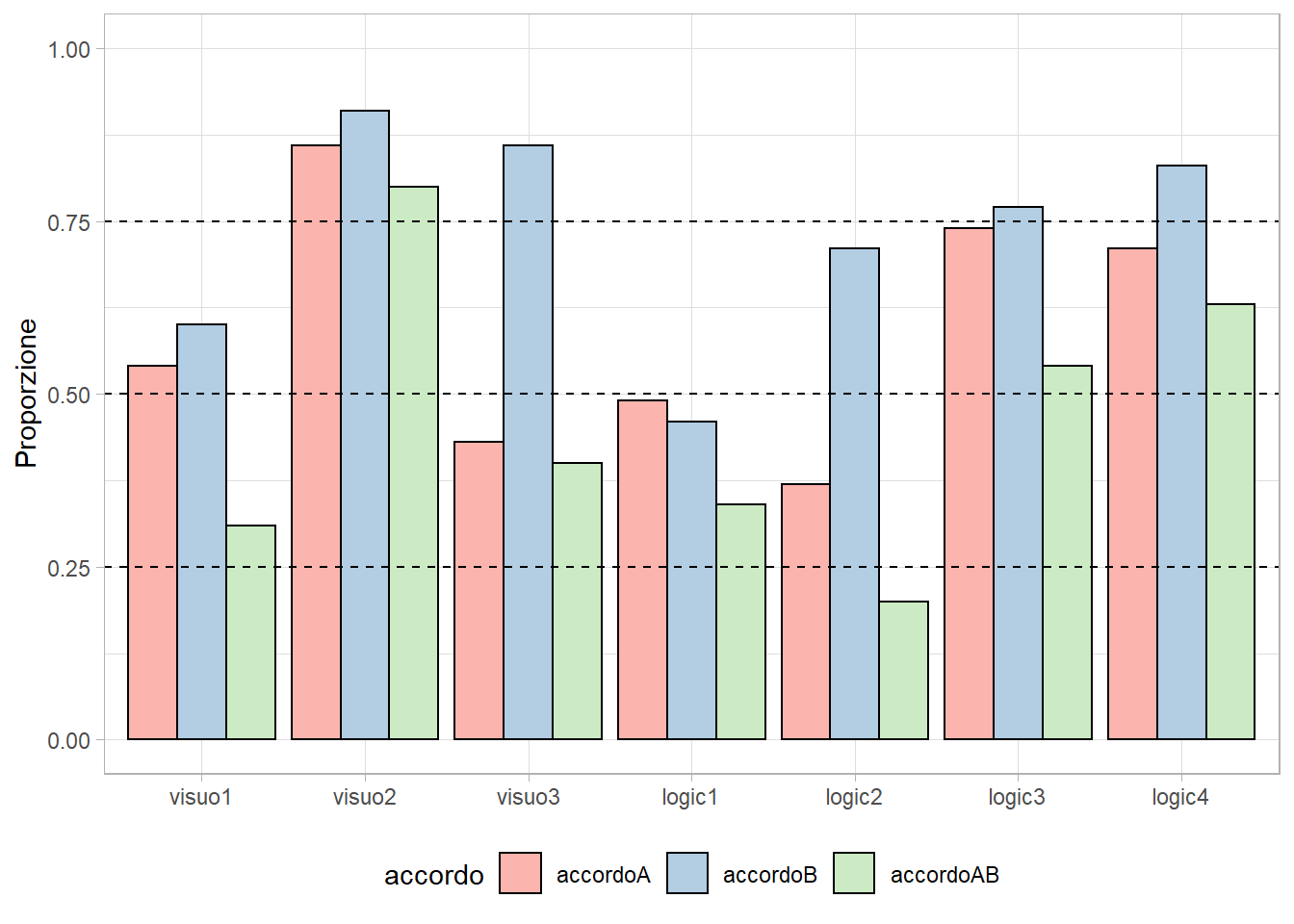
In questo caso calcolo l'accordo sui distrattori, quindi non considero solo la risposta corretta ma anche il distrattore che è stato scelto.
NB: I DISTRATTORI SONO RICODIFICATI NELLA LORO MACRO-CATEGORIA.
::: {.panel-tabset}
## Tabella
```{r}
rm(list = ls())
IRT <- function(theta, a = 1, b = 0, c = 0,e = 1) {
y <- c + (e - c) * exp(a * (theta - b)) / (1 + exp(a * (theta - b)))
y[is.na(y)] = 1
return(y)
}
irt.icc = function(model) {
item_par = model$item
est_theta = seq(-4,4, length.out=1000)
item_prob = list()
if (any(grep("guess", colnames(item_par))) == F) {
for (i in 1:nrow(item_par)) {
item_prob[[i]] = data.frame(theta = est_theta)
item_prob[[i]]$it_p = IRT(item_prob[[i]]$theta,
b = item_par[i, "xsi.item"],
a = item_par[i, "B.Cat1.Dim1"])
item_prob[[i]]$item = item_par[i, "item"]
}
} else {
for (i in 1:nrow(item_par)) {
item_prob[[i]] = data.frame(theta = est_theta)
item_prob[[i]]$it_p = IRT(item_prob[[i]]$theta,
b = item_par[i, "AXsi_.Cat1"],
a = item_par[i, "B.Cat1.Dim1"],
c = item_par[i, "guess"])
item_prob[[i]]$item = item_par[i, "item"]
}
}
p = do.call("rbind", item_prob)
gp = ggplot(p,
aes(x = theta, y = it_p, group = item, col =
item)) + geom_line(lwd = 1)
object = list(prob.data = p,
icc.graph = gp)
return(object)
}
data = read.csv("data/data_recode.csv",
header =T,
sep = ",")
# facciamo pulizia
data = data[data$data.accetto.non.accetto %in% 1, ]
data = data[!data$data.DistributionChannel %in% "preview", ]
data = data[!grepl("13/12", data$data.StartDate), ]
# prendo solo i dati completi
d = data[data$data.Finished %in% 1, ]
# rinomino i distrattori
d.r = d[, -c(1:4)]
for (i in 1:nrow(d.r)) {
for (j in 1:ncol(d.r)) {
if (is.na(d.r[i,j]) == T) {
d.r[i,j] = d.r[i,j]
} else if (d.r[i,j] == "correct") {
d.r[i,j] = d.r[i,j]
} else if (d.r[i, j] == "wp.copy.ic.flip") {
d.r[i, j] = "ic"
} else if (grepl("ic.", d.r[i,j]) ==T) {
d.r[i,j] = "ic"
} else if ( grepl("r.", d.r[i,j])) {
d.r[i,j] = "r"
} else if (grepl("wp.", d.r[i,j])) {
d.r[i,j] = "wp"
}
}
}
#| label: accordo.summary
#| tbl-cap-location: top
#| tbl-cap: Accordo ENTRO e TRA i set
#| tbl-subcap: Accordo calcolato considerando i singoli distrattori
d.r = d.r[, c("a_1", "a1_1", "b_visuo1", "b1_visuo1",
"a_2", "a1_2", "b_visuo2", "b1_visuo2",
"a_3", "a1_3", "b_visuo3", "b1_visuo3",
"a_logic1", "a1_logic1", "b_logic1", "b1_logic1",
"a_logic2", "a1_logic2", "b_logic2", "b1_logic2",
"a_logic3", "a1_logic3", "b_logic3", "b1_logic3",
"a_logic4", "a1_logic4", "b_logic4", "b1_logic4")]
tempA = NULL
pa = NULL
tempB = NULL
pb = NULL
for (i in seq(1,ncol(d.r), by = 4)) {
tempA = d.r[,i] == d.r[, i+1]
pa = cbind(pa, tempA)
tempB = d.r[,i+2] == d.r[, i+3]
pb = cbind(pb, tempB)
}
d.copy = d.r
for (i in 1:nrow(d.r)) {
for (j in seq(1,ncol(d.r), by = 4)) {
if (is.na(d.r[i, j]) == T | is.na(d.r[i, j+1]) == T) {
d.copy[i, j] = NA
} else if (d.r[i, j] == d.r[i, j+1]) {
d.copy[i, j] = d.r[i, j]
} else {
d.copy[i, j] = paste(d.r[i, j], d.r[i, j+1])
}
if (is.na(d.r[i, j+2]) == T | is.na(d.r[i, j+3]) == T) {
d.copy[i, j+2] = NA
} else if (d.r[i, j+2] == d.r[i, j+3]) {
d.copy[i, j+2] = d.r[i, j+2]
} else {
d.copy[i, j+2] = paste(d.r[i, j+2], d.r[i, j+3])
}
}
}
d.copy = d.copy[, seq(1,ncol(d.r), by = 2)]
# prima analisi molto molto dettagliata va proprio a vedere se sono stati scelti gli stessi per ogni possibile matrice
temp = NULL
p = NULL
for (i in seq(1,ncol(d.copy), by = 2)) {
temp = d.copy[,i] == d.copy[, i+1]
p = cbind(p, temp)
}
colnames(p)[1:3] = paste0("visuo", 1:3)
colnames(p)[4:ncol(p)] = paste0("logic", 1:4)
accordo.summary = data.frame(stimolo = colnames(p),
accordoA = round(colSums(pa, na.rm = T)/nrow(pa), 2),
accordoB = round(colSums(pb, na.rm = T)/nrow(pb), 2),
accordoAB = round(colSums(p, na.rm = T)/nrow(p), 2))
kable(accordo.summary, row.names = F)
```
## Grafico
```{r}
acc.sum.l = reshape(accordo.summary,
idvar = "stimolo",
times = names(accordo.summary)[-1],
timevar = "accordo",
varying = list(names(accordo.summary)[-1]),
direction = "long",
v.names = "prop")
acc.sum.l$accordo = factor(acc.sum.l$accordo,
levels = c("accordoA", "accordoB", "accordoAB"))
acc.sum.l$stimolo = factor(acc.sum.l$stimolo,
levels = c("visuo1",
"visuo2",
"visuo3",
"logic1",
"logic2",
"logic3",
"logic4"))
ggplot(acc.sum.l,
aes(x = stimolo, y = prop, fill = accordo)) + geom_bar(colour = "black",
stat = "identity",
position = position_dodge()) +
scale_fill_brewer(palette = "Pastel1") + theme_light() +
theme(legend.position = "bottom") + ylim(0,1) +
geom_hline(yintercept=.25, linetype="dashed")+
geom_hline(yintercept=.50, linetype="dashed")+
geom_hline(yintercept=.50, linetype="dashed")+
geom_hline(yintercept=.75, linetype="dashed") +
ylab("Proporzione") +
theme(axis.title.x = element_blank())
```
:::
# Rasch
::: {.panel-tabset}
## Fit
```{r}
#| tbl-cap-location: top
#| tbl-cap: Fit del modello di Rasch
#| tbl-subcap: Modello fittato sulle quaterne di item
d.rasch = d.r
for (i in 1:nrow(d.rasch)) {
for (j in 1:ncol(d.rasch)) {
if (is.na(d.rasch[i, j]) == T) {
d.rasch[i, j] = NA
} else if (d.rasch[i, j] == "correct") {
d.rasch[i, j] = as.integer(1)
} else {
d.rasch[i, j] = as.integer(0)
}
}
}
for (i in 1:ncol(d.rasch)) {
d.rasch[,i] = as.integer(d.rasch[,i])
}
# devo selezionare gli item a 4 a 4
temp.data = NULL
rasch.model = list()
rasch.fit = list()
for (i in seq(1, ncol(d.rasch), by = 4)) {
temp.data = d.rasch[, i:(i+3)]
rasch.model[[i]] = tam.mml(temp.data, verbose = F)
names(rasch.model)[[i]] = colnames(temp.data)[1]
rasch.fit[[i]] = tam.modelfit(rasch.model[[i]], progress = F)
names(rasch.fit)[[i]] = colnames(temp.data)[1]
}
for (i in seq(1, ncol(d.rasch), by = 4)) {
assign(paste("fit", names(rasch.fit)[i], sep = "."),
rasch.fit[[i]]$fitstat)
}
list.fi = ls()[grep("fit.a", ls())]
fit.summary = NULL
temp = NULL
for(i in 1:length(list.fi)){
fit.summary = rbind(fit.summary, get(list.fi[i]))
}
rownames(fit.summary) = list.fi
rownames(fit.summary)[1:3] = gsub("a_", "visuo", rownames(fit.summary)[1:3])
rownames(fit.summary)[4: nrow(fit.summary)] = gsub("a_", "", rownames(fit.summary)[4: nrow(fit.summary)])
for(i in 1:ncol(fit.summary)) {
fit.summary[,i] = round(fit.summary[,i], 2)
}
kable(fit.summary)
```
## Item (tabella)
```{r}
#| label: tbl-example
#| tbl-cap: Parametri di difficoltà degli item
#| tbl-subcap:
#| - "Visuo spaziali"
#| - "Logiche"
#| layout-ncol: 2
for (i in seq(1, ncol(d.rasch), by = 4)) {
assign(paste("item.par", names(rasch.model)[i], sep = "."),
rasch.model[[i]]$item_irt)
}
list.it.par = ls()[grep("item.par.a", ls())]
item.par.summary = NULL
temp = NULL
for(i in 1:length(list.it.par)){
item.par.summary = rbind(item.par.summary, get(list.it.par[i]))
}
itempar.sum = item.par.summary
item.par.summary$beta = round(item.par.summary$beta, 2)
kable(item.par.summary[-grep("logic", item.par.summary$item), ], row.names = F)
kable(item.par.summary[grep("logic", item.par.summary$item), ], row.names = F)
```
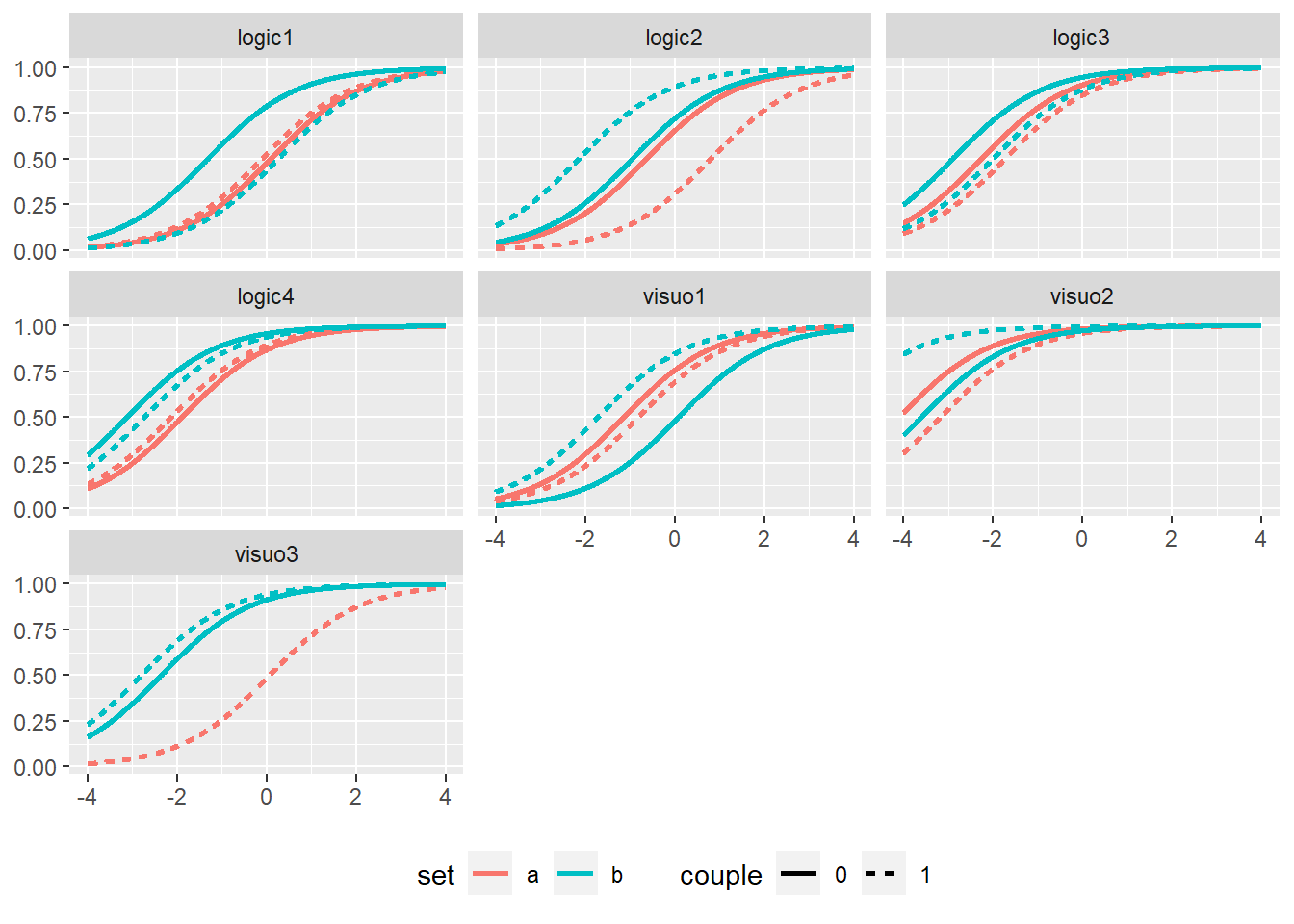
## Item (grafico tutti insieme)
```{r}
rasch.m = rasch.model[grep("a_", names(rasch.model))]
names(rasch.m)[1:3] = gsub("a_", "visuo", names(rasch.m)[1:3])
names(rasch.m)[4:length(rasch.m)] = gsub("a_", "", names(rasch.m)[4:length(rasch.m)])
icc.all = NULL
temp = NULL
for(i in 1:length(rasch.m)){
temp = irt.icc(rasch.m[[i]])$prob.data
temp$type = names(rasch.m)[i]
icc.all = rbind(icc.all, temp)
}
icc.all$set = gsub("_.*", "", icc.all$item)
icc.all$set = gsub("[0-9]", "", icc.all$set)
icc.all$couple = as.integer(gsub("\\D", "", icc.all$item))
icc.all$couple = ifelse(icc.all$couple > 10,
"1", "0")
ggplot(icc.all,
aes(x = theta, y = it_p, group = item,
col = set, linetype = couple)) + geom_line(lwd = 1) +
facet_wrap(~type) +
theme(legend.position = "bottom",
axis.title = element_blank())
```
:::